









Twelve Golden Rules From The Kitchen For Effective Leadership: ‘Mise En Place’
We’ve often been taught that “faster is better” when hustling to get a job done, but during my time working in the catering business, I learned...


7 min read

Let’s discuss how to convert events from an event-driven microservice architecture into relational tables in a warehouse like Snowflake. Here are a few things we’ll address:
Event Streams at Merit
At Merit, we’re building the leading verified identity platform. One key focus of our platform is data quality. Quality problems lead to first responders unable to check into disaster sites or parents unable to access ESA funds. In this blog post we’ll dive into how we tackled one source of quality issues: directly relying on upstream database schemas.
Under the hood, the Merit platform consists of a series of microservices. Each of these microservices has its own database. We use Snowflake as our data warehouse where we build dashboards both for internal use and for customers.
In the past, we relied upon an ETL tool (Stitch) to pull data out of microservice databases and into Snowflake. This data would become the main dbt sources used by our report models in BI.
This approach worked well, but as engineering velocity increased, we came up with a new policy that required we rethink this approach: no service should directly access another microservice’s database. This rule empowers microservices to change their database schemas however they like without worrying about breaking other systems.
Modern ETL tools like Fivetran and Stitch can flexibly handle schema changes - for example, if a new column is created they can propagate that creation to Snowflake. However, BI tools and dbt models aren’t typically written this way. For example, if a column your BI tool filters on has a name change in the upstream database, that filter will become useless and customers will complain.
The approach we used before required over-communicating about schema changes. Engineers would need to talk to Data before any change or it could risk a data outage. Tools that provide column-level lineage can improve detecting how schema changes affect dashboards. But a migration is still required should a used column be updated by a schema change.
This old approach frequently resulted in either busted dashboards or delayed schema changes. These issues were the exact reason engineering implemented the new policy.
The core challenge is contractual: in our old approach the contract between engineering and data was the database schema. But the database schema was intended to be a tool to help the microservice efficiently store and query data, not a contract.
So our solution was to start using an intentional contract: Events.
What are Events? Events are facts about what happened within your service. For example, somebody logged in or a new user was created. At Merit (and at many companies), we use an Event-Driven Architecture. That means that microservices primarily communicate information through events, often leveraging messaging platforms like Kafka.
Microservices consume messages from others that they’re interested in. We choose to use thick messages that store as much information as possible about each event - this means that consuming microservices can store and refer to event data instead of requesting fresh data from microservices. For distributed systems nerds: this improves Availability at the cost of Consistency.
Event schemas can still change, just like database schemas, but the expectation is that they are already a contract between this microservice and other systems. And the sole intention of events is to be this contract - unlike database schemas which are also used by microservices internally to store and query data. So, when an event schema changes, there already is a meeting between that team and all teams that consume the event - now Data is just another team at the meeting.
Events as Contracts
Each event output by a microservice is inserted into a single Kafka topic with a well-defined schema. This schema is managed as part of the Kafka Schema Registry. The Schema Registry doesn’t strictly enforce that events comply with the topic’s schema, but any microservice that produces an event that does not comply with the schema will cause downstream failures - a high-priority bug. These bad events are replayed with the correct schema when the microservice is fixed.
We use Avro to encode all of our event schemas. We also tried out Protobuf, but found that the Avro tooling was a bit better for Kafka.
Event schema design (what should the data contract be?) is a deep topic that we can only touch on briefly here. At a high level, we must design for change. A schema will almost always be tweaked and tuned over time as your product changes.
As an example, consider a LicenseCreated event. The internal License data model might have several boolean fields in its schema such as IsValid, IsCurrent, IsRestricted, etc. We would recommend instead modeling a License with a single Status field that has a VARCHAR representing the status of the License. New values are easier to add to a VARCHAR than adding or removing boolean fields.
One very useful feature of the Kafka Schema Registry is it can restrict changes that aren’t compatible with old schema versions. For example, if a data type is changed from an INT to a VARCHAR it will throw an error as the new schema is added. This can be an extra line of defense as schemas change. Read more about this awesome feature here.
OMG Contract
So we started consuming events from Kafka into Snowflake using Kafka’s Snowflake Connector.
The Snowflake Connector creates a new table for every Kafka topic and adds a new row for every event. In each row there’s a record_metadata column and a record_content column. Each column is a variant type in Snowflake.
Since we use thick messages we actually can consider ourselves done. The messages have as much information as the underlying database, so we could make queries against tables like the above.
However, working with these json blobs is much less convenient than a relational table for the following reasons:
Instead of repeatedly working with the above challenges, we decided to create a relational layer on top of the raw event streams. This takes the form of dbt macros that handle all of the above problems.
In order to make the dbt macros easier to write, we requested that engineering add some metadata to all of their events. This formalized the contract between engineering and data - any domain models that don’t comply with the contract will not be able to be used in reports unless the engineering team themself builds a custom pipeline. We named this the Obvious Model Generation (OMG) Contract since providing the metadata leads to obvious domain model generation. And we liked the acronym.
The OMG contract states that every Kafka message related to a domain model:
We now can run obvious model generation streams processing on all data that complies with the OMG contract.
Generic table pipelines via dbt Macros
After solidifying the OMG contract, we built the macros to execute obvious model generation. We wanted to make these as generic as possible while also following good engineering practices. We ended up building three macros that together process event streams into tables. All three macros take in streams_var - a list of all the event stream tables related to this domain model. We pull streams_var in from dbt_project.yml. We also take in streams_schema which defaults to ‘streams’ but allows overriding for our internal testing.
The first model is called stream_model_extract_columns which iterates through every row in the event stream tables to identify all of the columns that will be part of the domain model table.
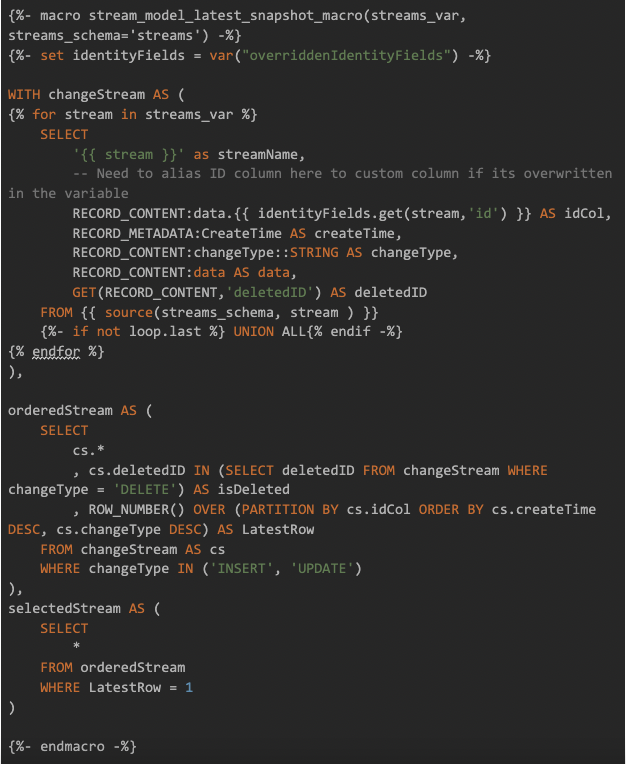
The second macro is called stream_model_latest_snapshot. It includes the logic to identify the latest state of every domain model object in the table, applying deletes when it finds them.
The final macro is called stream_model and it coordinates the usage of the first two. Particularly, it uses run_query() to run the first macro, then uses the results to execute the final query which leverages the second macro.
Now all we need to do is call the final macro in a dbt model and provide the list specified as a variable in dbt_project.yml. This file is in src_container.sql:
In src_container.yml we explicitly set and have tests for the columns we expect to be associated with this model. This is the first time we introduce the actual column names anywhere in our dbt code.
Future Ideas
We learned a lot from both working with event streams and building these macros.
One consideration that we haven’t discussed yet is materialization strategy. Since event stream tables are append-only, this is a natural fit for incremental models. At Merit, we haven’t worked much with incremental models, so we’re opting to start with views. As we roll this out to production models we’ll be doing a ton of performance testing to figure out the perfect materialization strategy for us.
We also plan on adding a dbt test that alerts whenever the columns of any domain model table changes. This may indicate that an unexpected change has happened to an event schema, which could affect dashboards.
These were certainly the most complicated dbt macros that we’ve built so far. This has inspired us to build a test framework to make sure that macros work as expected - including features like mocking run_query() calls. We’re considering open sourcing this framework - if you’re interested then let us know!
Let’s Talk!
We’ve used dbt macros to transform event streams into tables so that we don’t need our data pipelines to rely directly on database schemas. I’ll be talking about this more at Coalesce 2022 - come check out my talk Demystifying event streams: Transforming events into tables with dbt. You can also reach out to me in the dbt slack (@Charlie Summers) or LinkedIn.
We’ve often been taught that “faster is better” when hustling to get a job done, but during my time working in the catering business, I learned...
Your people are your most valuable asset and your biggest competitive advantage. Invest in them wisely, and they’ll take your company places you...
Big workforce initiatives thrive on strong collaboration between ecosystem partners; however, navigating those projects may sometimes be challenging....